Your business lives and dies by its data. An outage means lost revenue and a damaged reputation. You need your data center to be a fortress, but the power grid is an unreliable partner.
Data centers ensure uptime with multiple layers of redundancy. They use diverse power feeds, Uninterruptible Power Supplies (UPS), backup generators, and redundant cooling and network systems to eliminate every single point of failure.
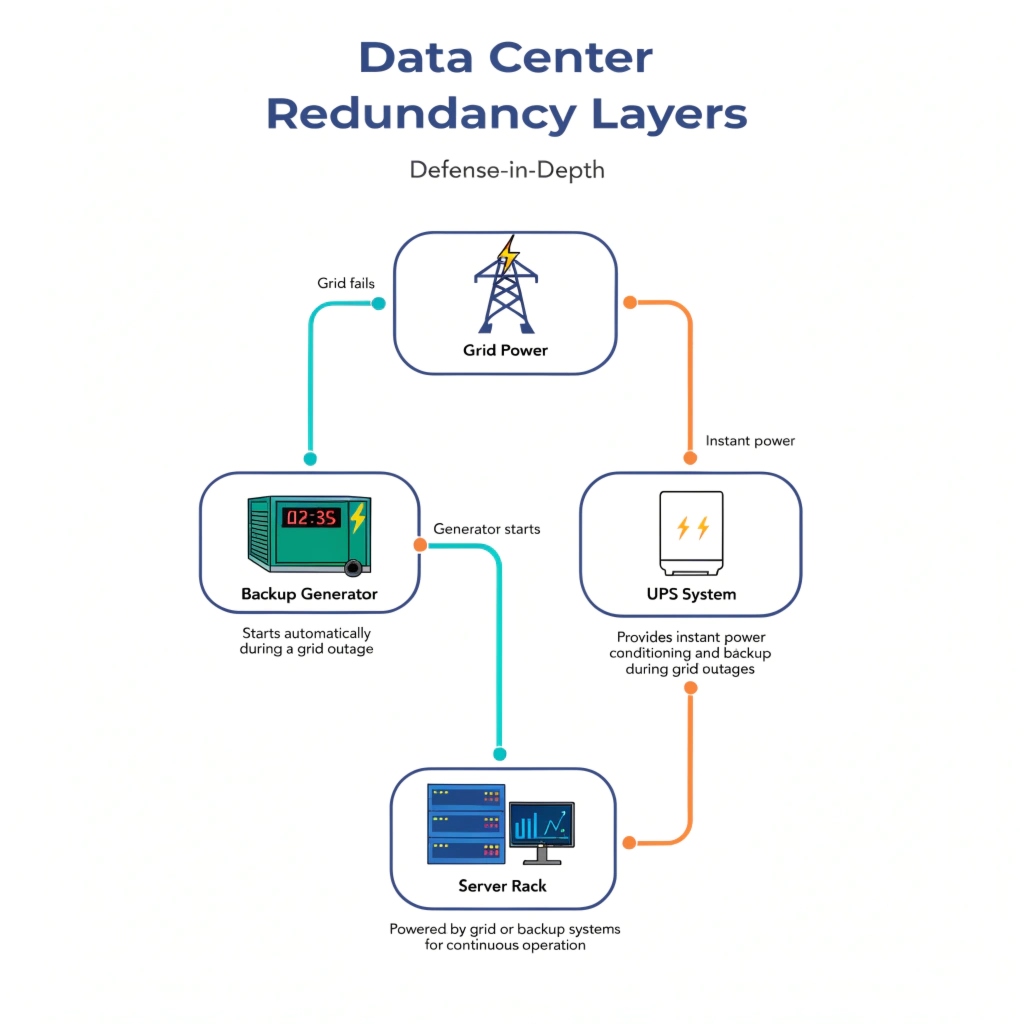
As a manufacturer, I know a UPS is a core part of this strategy. My insight is that a UPS is an energy storage machine customized for critical applications like data centers. It’s not just a big battery; it's the first line of defense that keeps everything running smoothly when the outside world gets chaotic. But it's only one piece of a larger puzzle. Let's look at how all these pieces fit together to create the "five nines" (99.999%) of uptime everyone talks about.
How to buy and use an uninterruptible power supply?
You need to buy a UPS, but the specifications are a sea of acronyms. Choosing the wrong one means you either overpay for features you don't need or, worse, buy a system that fails when you need it most.
To buy a UPS, first calculate your power load in Watts and add 25%. Then, determine your needed runtime. Finally, choose the right type—Online Double-Conversion is the standard for critical loads—to match your equipment's sensitivity.

A Practical Guide for Procurement Managers
Over my 10 years in this business, I've seen many clients get lost in the details. I always bring them back to a simple, three-step process. This is especially useful for procurement managers and system integrators who need to justify their choices.
- Calculate Your Load: Don't just guess. Add up the wattage of every server, switch, and storage device the UPS will protect. Then, add a 25% buffer. This gives you a safe operating margin and room for future growth.
- Determine Your Runtime: The goal isn't to run for hours on batteries. The goal is to provide a seamless bridge of 5-15 minutes, giving your backup generator time to start. The runtime determines the size and cost of your battery bank.
- Choose the Right Technology: For a data center, there is only one right answer: an Online Double-Conversion UPS. This technology completely isolates your equipment from the grid, rebuilding a perfect stream of power 24/7. It offers zero transfer time, which is essential for sensitive servers.
| Step | Action | Why it's Important |
|---|---|---|
| 1. Load Calculation | Add equipment Watts + 25% | Prevents overloading the UPS and allows for future expansion. |
| 2. Runtime Sizing | Define time needed to bridge to generator | Balances cost with the practical need for a graceful shutdown or generator startup. |
| 3. Technology Choice | Select Online Double-Conversion | Guarantees the highest level of power quality and zero transfer time for critical IT gear. |
What hardware does Google use in their data centers?
You want ultimate reliability, so you look to the giants like Google. You wonder what secret, magical hardware they use and if you can get it. The answer might surprise you and change how you think about power.
Google uses highly customized hardware, including a unique distributed power system. Instead of one huge central UPS, they place a small 12-volt battery directly on each server, creating a tiny, personal UPS for every machine.

The Philosophy of Distributed Power
Google's approach is fascinating because it turns conventional wisdom on its head. For decades, the model was to have a massive, centralized UPS protecting entire rooms of equipment. Google decentralized this. By putting a small battery on each server, they eliminated the central UPS as a single point of failure. If one server's battery fails, it only affects that one machine, not the whole rack. This is the ultimate expression of my insight: a UPS customized for a specific need. In this case, the need was for massive scale and fault isolation.
This approach also boosts efficiency. A large central UPS loses some energy just by running. By integrating the battery backup at the server level, Google saves a tremendous amount of power across its millions of servers. Now, is this practical for every business? No. The maintenance of millions of tiny batteries is complex. However, the philosophy is what's important. It teaches us to think creatively about reliability. As an OEM, we apply this thinking when designing modular UPS systems for our clients, allowing them to add power and redundancy as they grow, achieving a similar "scale-out" reliability model.
Do you need to be an IT expert to ensure uptime?
You are a procurement manager or facilities director, not an IT engineer. The technical language from vendors is overwhelming, and you worry about making a costly technical mistake while trying to make a sound business decision.
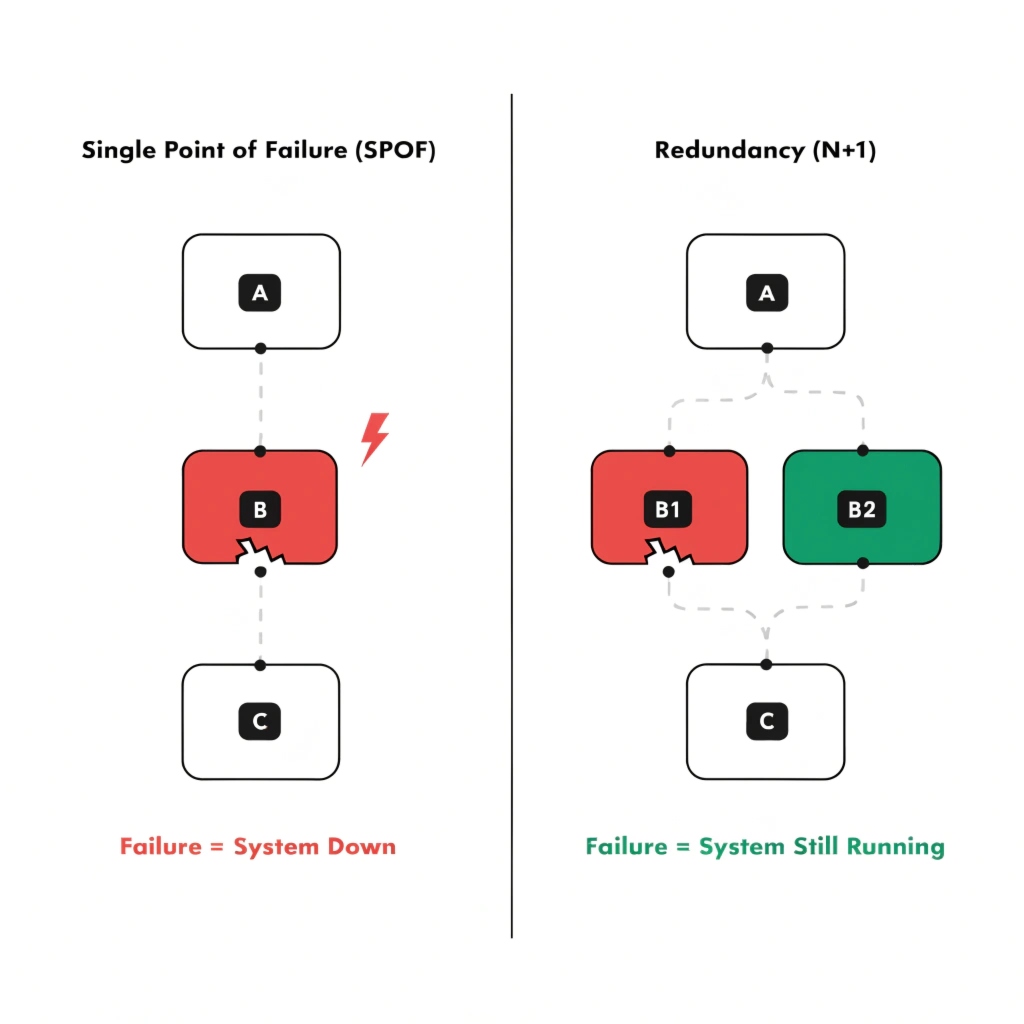
No, but you must understand two key IT principles: "redundancy" and "single point of failure" (SPOF). These ideas are the foundation of every reliable data center and guide all decisions about power, cooling, and networking.
The Language of Reliability
You don't need a computer science degree, but you need to speak the language of reliability. Let’s make it simple. A Single Point of Failure (SPOF) is any one component that, if it fails, brings the whole system down. Imagine a chain: its weakest link is a SPOF. The goal of data center design is to hunt down and eliminate every possible SPOF.
How do you do that? With redundancy. Redundancy simply means having duplicates. Instead of one power line, you have two. Instead of one cooling unit, you have two. This is where terms like "N+1" and "2N" come from. They are just a way of describing how much redundancy you have. As a UPS manufacturer, we design systems for all these levels. For a bank's data center, we might build a 2N system, which is a complete mirror image. For a smaller business, an N+1 system (one extra unit for backup) provides excellent reliability for the cost.
| Redundancy Level | What it Means | Example |
|---|---|---|
| N | The minimum required. No redundancy. | One UPS. If it fails, the system goes down. |
| N+1 | One extra component for backup. | Two UPS units where only one is needed. If one fails, the other takes over. |
| 2N | A full duplicate, mirror-image system. | Two independent power systems (UPS, panels, etc.). Maximum reliability. |
What is inside Google's Data Center?
The inner workings of a Google data center are a well-guarded secret. You might imagine a futuristic city from a sci-fi movie. While the reality is more practical, it's no less impressive in its scale and engineering.
Inside a Google data center are vast halls filled with custom-designed server racks, advanced cooling systems using outside air or recycled water, multiple layers of physical and digital security, and a highly efficient, multi-layered power system.

A Symphony of Efficiency and Redundancy
Walking into a modern hyperscale data center is an experience. You feel the cool air from carefully managed hot and cold aisles, designed to whisk heat away from the servers with maximum efficiency. You see thousands of servers in custom racks, all running on hardware designed for one purpose: performance at scale. There are no fancy brand names here; everything is custom-built.
The power infrastructure is the unseen hero. It starts outside with redundant utility feeds from different substations. Inside, massive backup generators stand ready. And at the server level, as we discussed, Google's unique battery-on-motherboard design provides the final, instant layer of protection. This entire system is designed to achieve an incredibly low Power Usage Effectiveness (PUE), a measure of how much energy is used by the IT equipment versus the overhead (like cooling). It shows that reliability and efficiency can go hand in hand. While most companies won't build a data center on Google's scale, the principles are universal: customize your solution, build in redundant layers, and always, always obsess over eliminating single points of failure.
Conclusion
Data center uptime relies on layers of redundancy in power, cooling, and networking. Understanding concepts like N+1 and choosing the right Online UPS are the first steps to building a reliable system.
